扩散模型是如何工作的:从零开始的数学原理
相关信息
本文翻译自 AI Summer 的工作人员 Sergios Karagiannakos, Nikolas Adaloglou 等几人发布的一篇文章,原文是 How diffusion models work: the math from scratch | AI Summer (theaisummer.com)
目录
译者前言
基于生成对抗网络 GANs 的 AI 生成图像往年在互联网不温不热,但就在最近这几个月, Open AI 于 2022 年 4 月初发布的 DALL-E 2 (基于 GPT Model) ,以及 stability.ai 于 2022 年 8 月底发布的 Stable Diffusion (基于 Diffusion Models) ,其生成的照片、画作的效果让人乍舌,随即引发了一股新的互联网 AI 创作热潮。
引发这一系列热潮的便是 Novel AI 于 2022 年 10 月初发布的,能够画各种精致二次元风格图片的 NovelAI Diffusion (基于 Stable Diffusion) 一下子把 AI 绘画推向风口浪尖。无数乐子人蜂拥而至,甚至有黑客把 Novel AI 的官网源码和模型全部扒了下来。 AI 创作数量极快,乍一看都很精致,而这些 “AI Based” 作品正在以一种极快的速度挤压创作者的空间,随即引发的便是关于伦理道德和法律的一系列疑问。
但是本文暂不讨论伦理道德等方面的问题(也许之后会写一篇文章讨论),仅仅先从技术角度和数学原理上简要介绍效果出众、“秒杀” GANs 且改变了人们对原本 AI 绘画认知的 Diffusion Models 的数学原理。
扩散模型是什么?
扩散模型 (Diffusion Models) 是一种新型的、先进的生成模型,可以生成各种高分辨率图像。在 OpenAI, Nvidia 和 Google 成功地训练了大规模的模型后,扩散模型已经吸引了很多人的注意。基于扩散模型的架构有 GLIDE, DALLE-2, Imagen 和 完全开源的 Stable Diffusion 。
其背后的原理是什么?
在这篇文章,我们将从基本原理开始挖掘。目前已经有许多不同的基于扩散模型的架构,我们将重点讨论其中最突出的一个,即由 Sohl-Dickstein et al 和 Ho. et al 2020 提出的去噪扩散概率模型 (DDPM, denoising diffusion probabilistic model) 。其它各种方法将不会具体讨论,如 Stable Diffusion 和 score-based models 。
提示
扩散模型与之前所有的生成方法有着本质的区别。直观地说,它们旨在将图像生成过程(采样)分解为许多小的“去噪”步骤
直观点说,模型可以在这些小的步骤中自我修正,并逐渐产生一个更好的样本。在某种程度上,这种完善表征的想法已经在 alphafold 等模型中得到了应用。但是,这种迭代过程使其采样速度很慢,至少与 GANs 相比。
扩散过程
扩散模型的基本思想是相当简单的。把输入图像
之后,神经网络被训练为通过逆转噪声过程来恢复原始数据。通过对反向过程进行建模,我们可以生成新的数据。这就是所谓的反向扩散过程,或者说是生成式模型的采样过程。
具体是怎样的?让我们深入其中的数学,让一切变得清晰起来。
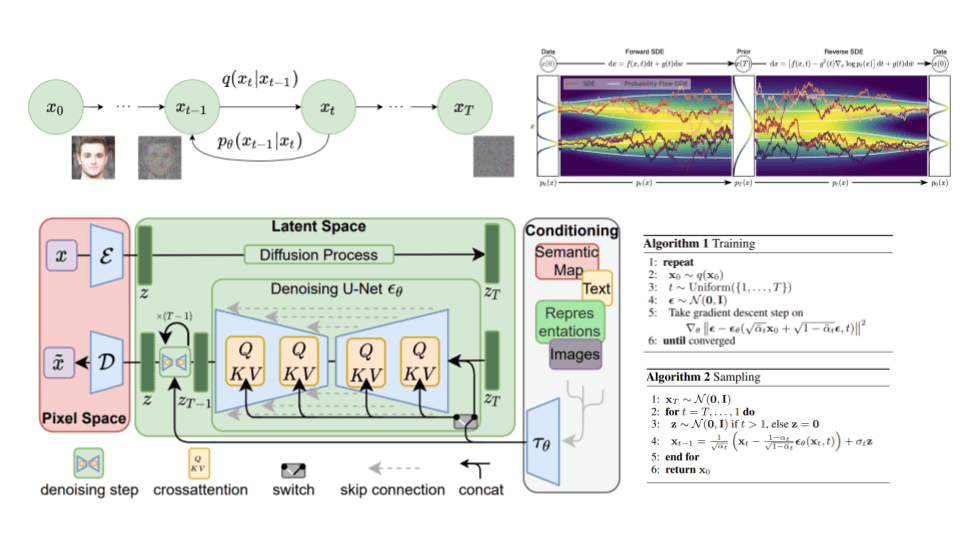
前向扩散
扩散模型可以被看作是潜在变量模型。“潜在”意味着我们指的是一个隐藏的连续特征空间。以这种方式,扩散模型可能看起来类似于 变分自动编码器 (VAEs) 。
在实践中,前向扩散是用一个马尔科夫链的
给定一个数据点
前向扩散过程
图片修改自 Ho et al. 2020
由于我们处于多维情况下,
因此,我们可以自
其中,
到目前为止,看起来还不错?并不!对于时间步长
重参数化技巧 (Reparametrization Trick) 对此提供了一个魔法般的补救办法。
重参数化技巧:在任何时间步长上的可操作闭式采样
如果我们定义
注
由于所有时间段都有相同的高斯噪声,我们从现在开始只使用符号
因此,为了产生一个样本,我们可以使用如下公式:
由于
方差表
方差参数

分别来自线性(上面)和余弦时间表(下面)的潜伏样本
图片来自 Nichol & Dhariwal 2021
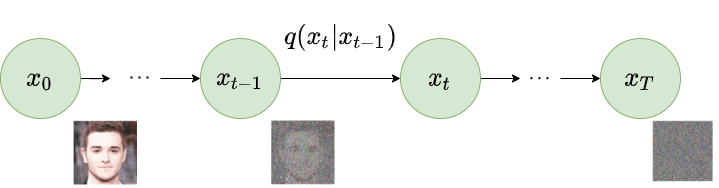
反向扩散
当
问题是我们如何对反向扩散过程进行建模。
用神经网络逼近反向过程
在实际情况中,我们不知道
相反,我们用一个参数化的模型
反向扩散过程
图片修改自 Ho et al. 2020
如果我们对所有的时间步数应用反向公式
通过对时间段
训练一个扩散模型
如果我们退一步讲,我们可以注意到,
我们来分析一下这些内容:
可以当作是一个重建项 (reconstruction term) ,类似于变量自动编码器 ELBO 中的那个。在 Ho et al 2020 的研究中,这一项是用一个单独的解码器学习的。 显示了 与标准高斯是多么的相似。注意到,整个项都没有可训练的参数,因此,训练过程这个项会被忽略。 - 最后的第三项
也表示为 ,描述了期望的去噪步骤 与近似项 之间的差异。
很明显,通过 ELBO ,最大化的可能性可以归结为学习去噪步骤
注
尽管
直观地说,画家(这个模型)需要一个参考图像 (
换句话说,我们可以在噪声水平
注
这个小技巧为我们提供了一个完全可操作的 ELBO 。上述属性还有一个重要的副作用,正如我们在重参数化技巧中已经看到的,我们可以将
其中
通过合并最后两个方程,现在每个时间步长将有一个平均数
因此,我们可以使用一个神经网路
因此,损失函数(ELBO中的去噪项)可以表示为:
这实际上告诉我们,该模型不是预测分布的平均值,而是预测每个时间点
Ho et.al 2020 对实际损失项做了一些简化,因为他们忽略了一个加权项。简化后的版本优于完整的目标:
作者发现,优化上述目标比优化原始 ELBO 效果更好。这两个方程的证明可以在 Lillian Weng 的这篇优秀文章或 Luo et al. 2022 中找到。
此外,Ho et. al 2020 决定保持方差固定,让网络只学习均值。后来 Nichol et al. 2021 对此进行了改进,他们让网络学习协方差矩阵

DDPMs 的训练和采样算法
图片来自 Ho et al. 2020
架构
到目前为止,我们还没有提到的一件事是模型的架构是什么样子的。请注意,模型的输入和输出应该是相同大小的。
为此, Ho et al. 采用了一个 U-Net 。如果你对 U-Net 不熟悉,请随时查看我们过去关于 主要 U-Net 架构 的文章。简而言之, U-Net 是一种对称的架构,其输入和输出的空间大小相同,在相应特征维度的编码器和解码器块之间使用 跳过连接 。通常情况下,输入图像首先被降频,然后被升频,直到达到其初始尺寸。
在 DDPMs 的原始实现中, U-Net 由宽 ResNet 块 、 分组归一化 以及 自我注意 块组成。
扩散时间段
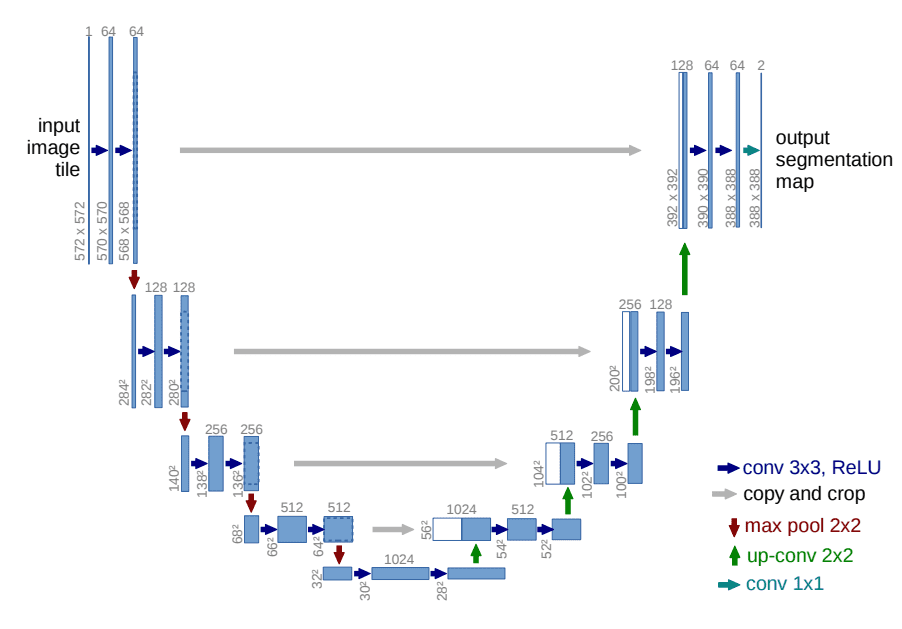
U-Net 的架构
图片来自 Ronneberger et al.
条件性图像生成:引导扩散
图像生成的一个关键方面是调节采样过程,以操纵生成的样本。在这里,这也被称为引导性扩散。
甚至有一些方法将图像嵌入到扩散中,以便“引导”生成。从数学上讲,引导指的是用一个条件
在每个时间点都能看到调节的事实,这可能是文字提示的优秀样本的一个很好的理由。
一般来说,引导扩散模型的目的是学习
因为梯度算子
再加上一个指导性的标量项
利用这一表述,让我们对分类器和无分类器的引导进行区分。接下来,我们将介绍两个旨在注入标签信息的方法系列。
分类指导
Sohl-Dickstein et al. 以及后来的 Dhariwal 和 Nichol 表明,我们可以使用第二个模型,即分类器
我们可以建立一个具有均值
由于
在 Nichol et al. 著名的 GLIDE 论文 中,作者扩展了这个想法,并使用 CLIP 嵌入 来指导扩散。 Saharia et al. 提出的 CLIP 由一个图像编码器
因此,我们可以用它们的点积来扰动梯度:
结果是,它们设法将生成过程“引向”用户定义的文本标题。

分类器引导的扩散采样算法
图片来自 Dhariwal & Nichol 2021
无分类指导
使用与之前相同的表述,我们可以将无分类器的引导扩散模型定义为:
正如 Ho & Salimans 所提议的那样,不需要第二个分类器模型就可以实现指导作用。事实上,他们使用的是完全相同的神经网络,而不是训练一个单独的分类器,作者将条件性扩散模型
注
请注意,这也可以用来“注入”文本嵌入,正如我们在分类器指导中显示的那样
这个公认的“怪异”过程有两个主要优点:
- 它只使用一个单一的模型来指导扩散。
- 当对难以用分类器预测的信息(如文本嵌入)进行调节时,它简化了指导。
Saharia et al. 提出的 Imagen 在很大程度上依赖于无分类器的引导,因为他们发现这是一个关键因素去产生具有强大图像-文本对准的生成样本。关于 Imagen 方法的更多信息,请看 AI Coffee Break 与 Letitia 的这段 YouTube 视频:
提示
如果长时间加载不出来,说明你的网络无法访问 YouTube
YouTube 视频
扩大扩散模型的规模
你可能会问这些模型的问题是什么。好吧,将这些 U-Net 扩展到高分辨率的图像中,在计算上是非常昂贵的。这给我们带来了两种将扩散模型扩展到高分辨率的方法:级联扩散模型和潜伏扩散模型。
级联扩散模型
Ho et al. 2021 引入了级联扩散模型,以努力产生高保真的图像。级联扩散模型包括一个由许多连续扩散模型组成的管道,生成分辨率越来越高的图像。每个模型通过连续地对图像进行上采样并增加更高分辨率的细节,生成一个比前一个质量更好的样本。为了生成一个图像,我们从每个扩散模型中依次取样。
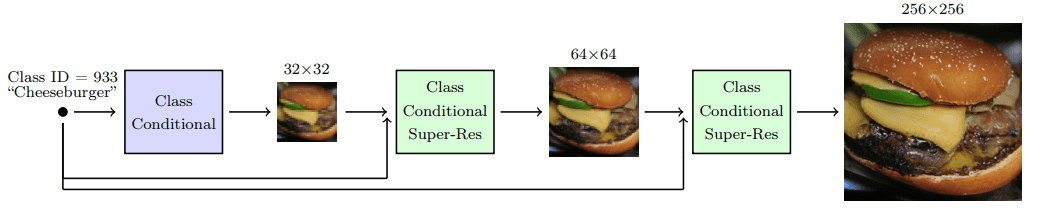
级联扩散模型管道
图片来自 Ho & Saharia et al.
为了获得级联架构的良好效果,对每个超级分辨率模型的输入进行强有力的数据增强是至关重要的。为什么呢?因为它可以减轻之前级联模型的复合误差,以及由于训练-测试不匹配造成的误差。
研究发现,高斯模糊是实现高保真度的一个关键转变,他们把这种技术称为调节增强。
Stable Diffusion: 潜在扩散模型
潜在扩散模型是基于一个相当简单的想法:我们不是直接在高维输入上应用扩散过程,而是将输入投射到一个较小的潜伏空间,并在那里应用扩散。
更详细地说, Rombach et al. 建议使用编码器网络将输入编码为潜伏表示,即
如果一个典型的扩散模型 (DM) 的损失被表述为:
然后,给定编码器
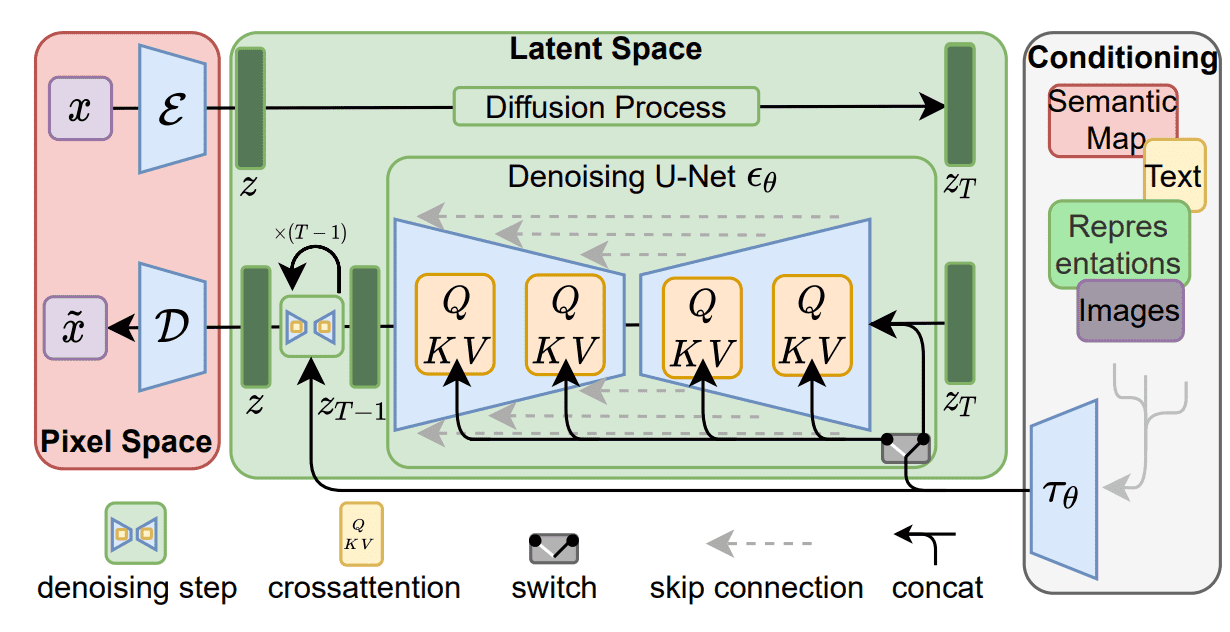
潜伏的扩散模型
图片来自 Rombach et al
欲了解更多信息,请看这个 YouTube 视频:
提示
如果长时间加载不出来,说明你的网络无法访问 YouTube
YouTube 视频
基于评分的生成模型
在 DDPM 论文发表的同时, Song and Ermon 提出了一种不同类型的生成模型,似乎与扩散模型有许多相似之处。基于评分的模型利用评分匹配和 Langevin 动力学来解决生成式学习。
相关信息
- 评分匹配 (Score-matching) 指的是对数概率密度函数梯度的建模过程,也被称为评分函数。
- Langevin 动力学 (Langevin dynamics) 是一个迭代过程,可以从一个分布中只使用其评分函数来抽取样本
其中
假设我们有一个概率密度
然后通过使用 Langevin 动力学,我们可以使用近似的评分函数直接从
提示
引导式扩散模型使用这种基于评分的模型的表述,因为它直接学习
为基于评分的模型添加噪音:噪声条件得分网络 (NCSN)
提示
到目前为止的问题是:在低密度地区,估计的评分函数通常是不准确的,因为那里的数据点很少。因此,使用 Langevin 动力学采样的数据质量并不好
他们的解决方案是对数据点进行噪声扰动,然后在噪声数据点上训练基于评分的模型。事实上,他们使用了多种规模的高斯噪声扰动。
因此,添加噪声是使 DDPM 和基于评分的模型都能工作的关键。
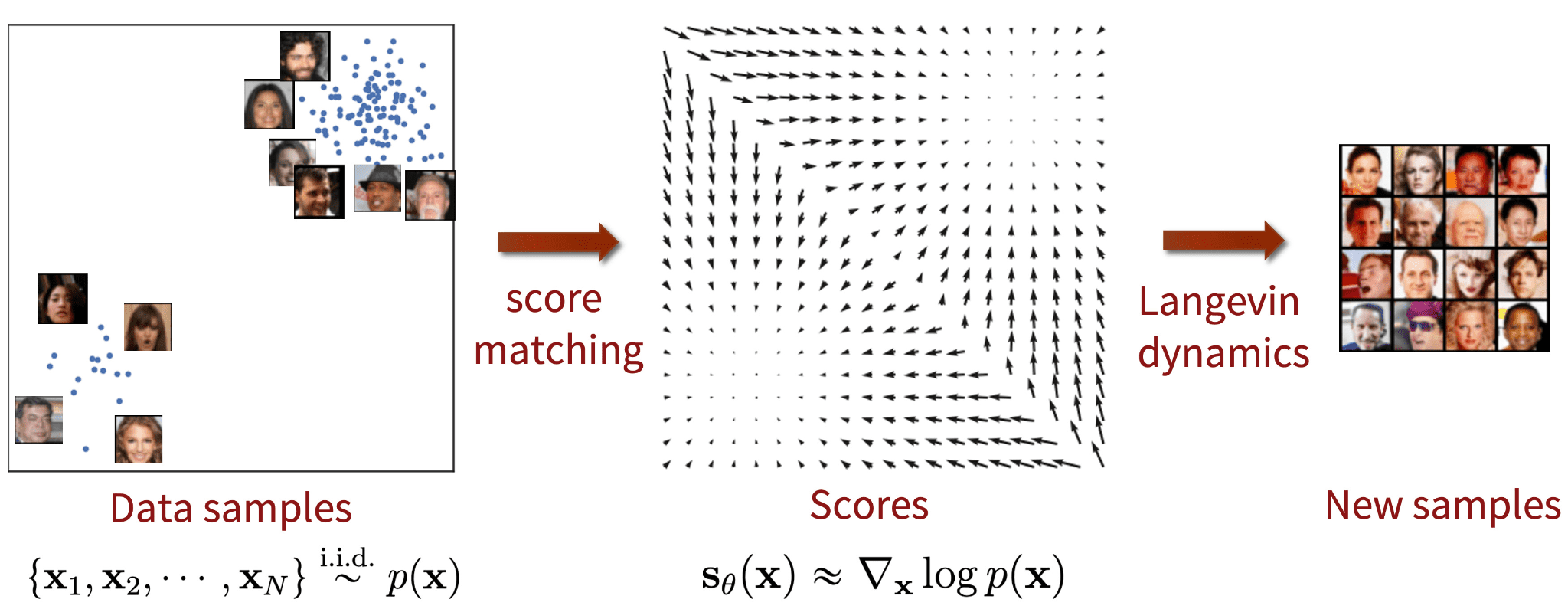
基于评分的生成模型与评分匹配以及 Langevin 动力学
图片来自 Generative Modeling by Estimating Gradients of the Data Distribution
在数学上,给定数据分布
然后我们训练一个网络
通过随机微分方程 (SDE) 进行基于评分的生成性建模
Song et al. 2021 探讨了基于评分的模型与扩散模型的联系。为了将 NSCNs 和 DDPMs 都囊括在同一伞下,他们提出了以下建议。
我们不使用有限数量的噪声分布来扰动数据,而是使用连续的分布,这些分布根据扩散过程随时间演变。这个过程由一个规定的随机微分方程 (SDE) 来模拟,它不依赖于数据,也没有可训练的参数。通过逆转这个过程,我们可以生成新的样本。

通过随机微分方程 (SDE) 进行基于评分的生成性建模
图片来自 Song et al. 2021
我们可以把扩散过程
其中,
提示
为了理解我们为什么使用 SDE ,这里有一个提示: SDE 的灵感来自于布朗运动,在布朗运动中,一些粒子在介质内随机移动。粒子运动的这种随机性模拟了数据上的连续噪声扰动
在对原始数据分布进行足够长时间的扰动后,被扰动的分布会变得接近于一个可操作的噪声分布。
为了产生新的样本,我们需要逆转扩散过程。该 SDE 被选择为有一个相应的封闭形式的反向 SDE:
为了计算反向 SDE ,我们需要估计评分函数
其中
提示
有许多解决反向 SDE 的方案,我们在此不作分析。请务必查看原始论文或作者的 这篇优秀博文
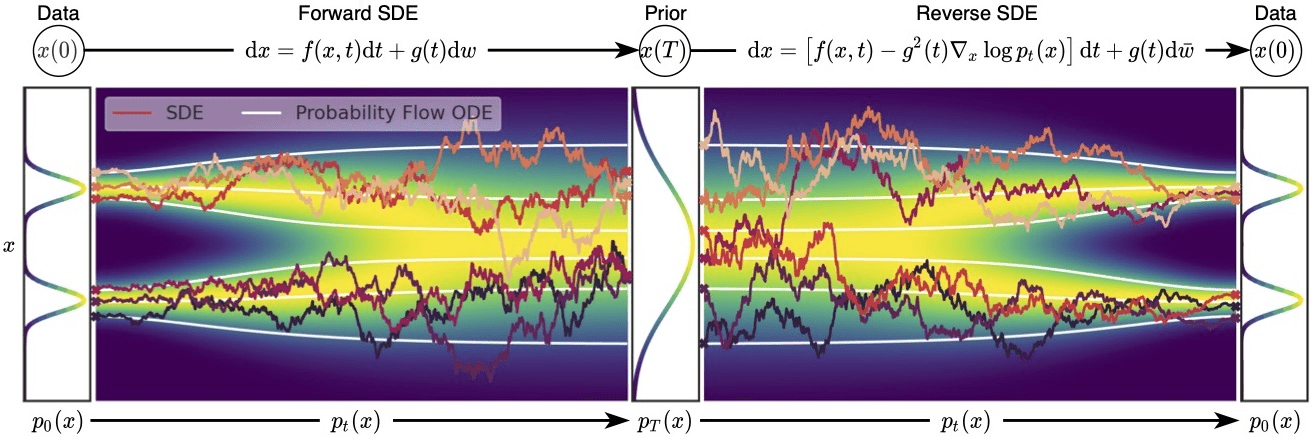
通过 SDEs 进行基于评分的生成性建模的概述
图片来自 Song et al. 2021
总结
让我们对这篇博文中所学到的主要内容做一个简单的总结。
- 扩散模型的工作原理是通过一系列的 TT 步骤将高斯噪声逐渐添加到原始图像中,这个过程被称为扩散。
- 为了对新数据进行采样,我们使用神经网络对反向扩散过程进行近似。
- 模型的训练是基于证据下界 (ELBO) 的最大化。
- 我们可以将扩散模型置于图像标签或文本嵌入的条件下,以便“指导”扩散过程。
- 级联扩散和潜伏扩散是两种将模型扩展到高分辨率的方法。
- 级联扩散模型是连续的扩散模型,可以生成分辨率越来越高的图像。
- 潜伏扩散模型(像 Stable Diffusion )在较小的潜伏空间上应用扩散过程,以提高计算效率,使用变分自编码器进行向上和向下取样。
- 基于评分的模型也将一连串的噪声扰动应用到原始图像上。但它是用评分匹配和 Langevin 动力学来训练的。尽管如此,它最终的目标是相似的。
- 扩散过程可以被表述为一个 SDE 。解决反向 SDE 使我们能够生成新的样本。
最后,对于 扩散模型 和 VAE 或 AE 之间的更多联系,请查看 这些很棒的文章 。
引用
@article{karagiannakos2022diffusionmodels,
title = "Diffusion models: toward state-of-the-art image generation",
author = "Karagiannakos, Sergios, Adaloglou, Nikolaos",
journal = "https://theaisummer.com/",
year = "2022",
howpublished = {https://theaisummer.com/diffusion-models/},
}
参考文献
相关信息
[1] Sohl-Dickstein, Jascha, et al. Deep Unsupervised Learning Using Nonequilibrium Thermodynamics. arXiv:1503.03585, arXiv, 18 Nov. 2015
[2] Ho, Jonathan, et al. Denoising Diffusion Probabilistic Models. arXiv:2006.11239, arXiv, 16 Dec. 2020
[3] Nichol, Alex, and Prafulla Dhariwal. Improved Denoising Diffusion Probabilistic Models. arXiv:2102.09672, arXiv, 18 Feb. 2021
[4] Dhariwal, Prafulla, and Alex Nichol. Diffusion Models Beat GANs on Image Synthesis. arXiv:2105.05233, arXiv, 1 June 2021
[5] Nichol, Alex, et al. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. arXiv:2112.10741, arXiv, 8 Mar. 2022
[6] Ho, Jonathan, and Tim Salimans. Classifier-Free Diffusion Guidance. 2021. openreview.net
[7] Ramesh, Aditya, et al. Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv:2204.06125, arXiv, 12 Apr. 2022
[8] Saharia, Chitwan, et al. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. arXiv:2205.11487, arXiv, 23 May 2022
[9] Rombach, Robin, et al. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv:2112.10752, arXiv, 13 Apr. 2022
[10] Ho, Jonathan, et al. Cascaded Diffusion Models for High Fidelity Image Generation. arXiv:2106.15282, arXiv, 17 Dec. 2021
[11] Weng, Lilian. What Are Diffusion Models? 11 July 2021
[12] O'Connor, Ryan. Introduction to Diffusion Models for Machine Learning AssemblyAI Blog, 12 May 2022
[13] Rogge, Niels and Rasul, Kashif. The Annotated Diffusion Models. Hugging Face Blog, 7 June 2022
[14] Das, Ayan. An Introduction to Diffusion Probabilistic Models. Ayan Das, 4 Dec. 2021
[15] Song, Yang, and Stefano Ermon. Generative Modeling by Estimating Gradients of the Data Distribution. arXiv:1907.05600, arXiv, 10 Oct. 2020
[16] Song, Yang, and Stefano Ermon. Improved Techniques for Training Score-Based Generative Models. arXiv:2006.09011, arXiv, 23 Oct. 2020
[17] Song, Yang, et al. Score-Based Generative Modeling through Stochastic Differential Equations. arXiv:2011.13456, arXiv, 10 Feb. 2021
[18] Song, Yang. Generative Modeling by Estimating Gradients of the Data Distribution. 5 May 2021
[19] Luo, Calvin. Understanding Diffusion Models: A Unified Perspective. 25 Aug. 2022
许可协议
Copyright © 2019-2026